Erklärbare KI zur Textzusammenfassung von Rechtsdokumenten

Nina Hristozova, Data Scientist, und Milda Norkute, Senior Designerin, Thomson Reuters, besprechen Sie erklärbare KI für die Textzusammenfassung von Rechtsdokumenten und die Anpassung der Erklärung Ihres Modells an die Bedürfnisse Ihrer Benutzer.
Erklärbare KI
Erklärbare Künstliche Intelligenz (XAI) ist ein Überbegriff für eine Reihe von Techniken, Algorithmen und Methoden, die die Ergebnisse von Systemen der künstlichen Intelligenz (KI) mit Erklärungen begleiten. Es adressiert die oft unerwünschte Black-Box-Natur vieler KI-Systeme und ermöglicht es Benutzern anschließend, KI-Lösungen zu verstehen, ihnen zu vertrauen und fundierte Entscheidungen zu treffen [1].
Hintergrund
Die schnell wachsende Einführung von KI-Technologien, die undurchsichtige tiefe neuronale Netze verwenden, hat sowohl das akademische als auch das öffentliche Interesse an Erklärbarkeit geweckt. Diese Ausgabe erscheint in der populären Presse, in Branchenpraktiken, Vorschriften sowie in vielen neueren Artikeln, die in KI und verwandten Disziplinen veröffentlicht wurden.
Abbildung 1 unten zeigt die Entwicklung der Anzahl der Gesamtpublikationen, deren Titel, Abstract oder Schlüsselwörter sich auf das Gebiet der XAI beziehen, in den letzten Jahren. Die Daten wurden 2019 von Scopus abgerufen. Wir können sehen, dass der Bedarf an interpretierbaren KI-Modellen im Laufe der Zeit gewachsen ist, aber erst 2017 hat sich das Interesse an Techniken zur Erklärung von KI-Modellen (in grün) in der gesamten Forschungsgemeinschaft durchgesetzt [1 ]. Einer der Gründe dafür könnte die 2016 in der Europäischen Union (EU) eingeführte „DSGVO“, auch bekannt als „Datenschutz-Grundverordnung“, sein, die ein „Recht auf Erklärung“ beinhaltet.

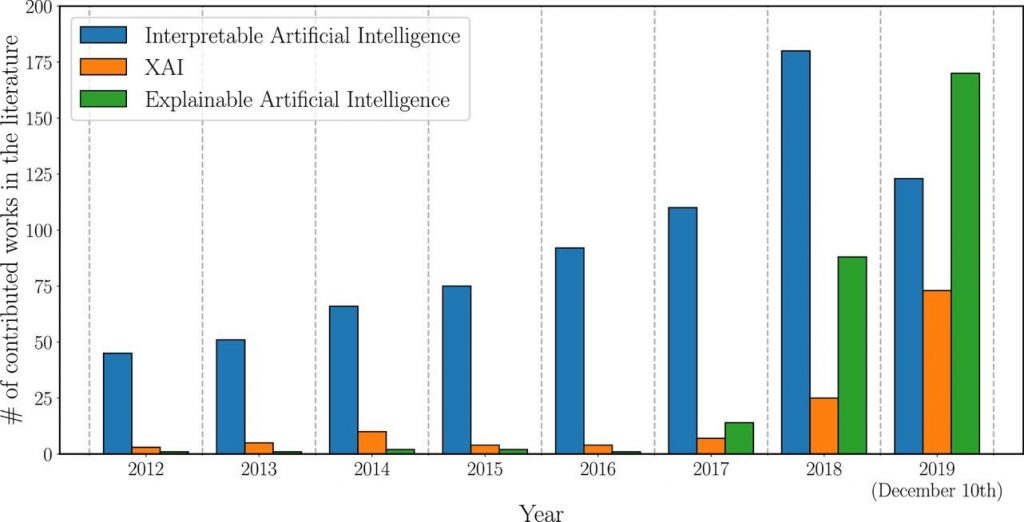
In Abbildung 1 sehen wir auch ein allmählich wachsendes Interesse an Interpretierbarkeit. Erklärbarkeit darf nicht mit Interpretierbarkeit verwechselt werden. Bei letzterem geht es darum, inwieweit man Vorhersagen treffen kann was passieren wird, wenn sich Eingabe- oder algorithmische Parameter ändern. Es geht um die Fähigkeit, die Mechanik zu erkennen, ohne notwendigerweise zu wissen, warum. Erklärbarkeit hingegen ist das Ausmaß, in dem die interne Mechanik einer Maschine oder eines Deep-Learning-Systems mit menschlichen Begriffen erklärt werden kann [2]. Der Unterschied ist jedoch subtil. Wir werden uns für den Rest dieses Artikels auf die Erklärbarkeit konzentrieren, aber um mehr über die Interpretierbarkeit zu erfahren, siehe diese Ressource.
XAI für wen?
Der Zweck der Erklärbarkeit in KI-Modellen kann je nach Zielgruppe stark variieren. Im Allgemeinen können fünf Hauptzielgruppentypen identifiziert werden: Domänenexperten und Benutzer des Modells, die direkt mit seinen Ergebnissen interagieren, Benutzer, die von den Entscheidungen des Modells betroffen sind, Regulierungsbehörden, Ersteller des Modells – Datenwissenschaftler, Produkteigentümer und andere, Manager und Geschäftsführung Mitglieder [1]. Siehe Abbildung 2 unten, um mehr über die unterschiedlichen Erklärbarkeitsbedürfnisse einiger dieser Zielgruppen zu erfahren.

Beispielsweise besteht der Zweck der Erklärbarkeit für die Benutzer des Modells darin, dem Modell zu vertrauen, während Benutzer, die von Modellentscheidungen betroffen sind, von der Erklärbarkeit profitieren könnten, indem sie ihre Situation besser verstehen und überprüfen, ob die Entscheidungen fair waren. Da diese Zielgruppen unterschiedliche Ziele haben, bedeutet dies, dass eine Erklärung, die von einer Art von Zielgruppe als gut angesehen wird, für eine andere möglicherweise nicht ausreicht.
Modellspezifisches und modellunabhängiges XAI
Generell kann gesagt werden, dass es zwei Hauptansätze gibt, um interpretierbare Modelle zu entwickeln. Ein Ansatz besteht darin, anstelle von Black-Box-Systemen einfache, übersichtliche Modelle zu erstellen. aus einem Entscheidungsbaum können Sie beispielsweise Entscheidungsregeln einfach extrahieren. Dies ist jedoch nicht immer möglich und manchmal werden komplexere KI-Modelle benötigt. Der zweite Ansatz besteht also darin, Post-hoc-Erklärungen für komplexere oder sogar vollständige Black-Box-Modelle bereitzustellen. Der letztere Ansatz verwendet typischerweise modellunabhängige Erklärbarkeitsmethoden, die für jedes maschinelle Lernmodell verwendet werden können, von Support-Vektor-Maschinen bis hin zu neuronalen Netzen [3]. Zu den derzeit verfügbaren modellunabhängigen Methoden gehören Partial Dependence Plots (PDPs), Individual Conditional Expectation (ICE) Plots, globale Ersatzmodelle, Shapley Additive Explanations (SHAP) und Local Interpretable Model-agnostic Explanations (LIME) [4,5].
LIME hilft beispielsweise dabei, die Vorhersagen des Modells individuell nachvollziehbar zu machen. Die Methode erläutert den Klassifikator für eine bestimmte Einzelinstanz. Es manipuliert die Eingabedaten und erstellt eine Reihe künstlicher Daten, die nur einen Teil der ursprünglichen Attribute enthalten. Bei Textdaten werden verschiedene Versionen des Originaltextes erstellt, bei denen eine bestimmte Anzahl unterschiedlicher, zufällig ausgewählter Wörter entfernt wird. Diese neuen künstlichen Daten werden dann in verschiedene Kategorien eingeteilt. So können wir durch das Fehlen oder Vorhandensein bestimmter Schlüsselwörter ihren Einfluss auf die Klassifizierung des ausgewählten Textes erkennen. Grundsätzlich ist die LIME-Methode mit vielen verschiedenen Klassifikatoren kompatibel und kann mit Text-, Bild- und Tabellendaten verwendet werden. Dasselbe Muster lässt sich auch auf die Bildklassifikation anwenden, bei der die künstlichen Daten keinen Teil der ursprünglichen Wörter enthalten, sondern Bildausschnitte (Pixel) eines Bildes [5].

Aufmerksamkeit
Einige Blackbox-Modelle sind gar nicht mehr so Blackbox. Im Jahr 2016 erschien der erste Artikel, der einen Mechanismus vorstellte, der es einem Modell ermöglicht, automatisch (weich) nach Teilen eines Ausgangssatzes zu suchen, die für die Vorhersage eines Zielworts relevant sind [6]. 2017 folgte dann der Artikel Attention is All You Need [7], der den Aufmerksamkeitsmechanismus und die Transformer-Modelle vorstellte. Es könnte verschiedene Arten geben, Aufmerksamkeitstypen zu klassifizieren, aber zwei Hauptarten sind additive Aufmerksamkeit und Punktproduktaufmerksamkeit [8].
Allgemein stellt der Aufmerksamkeitsmechanismus Abhängigkeiten zwischen Input und Output her [9]. In traditionellen Deep-Learning-Modellen (LSTMs, RNNs) ist es für das Modell umso schwieriger, relevante Informationen aus den vergangenen Schritten zu behalten, je länger die Eingabe ist. Aus diesem Grund möchten wir dem Modell signalisieren, worauf es sich konzentrieren und worauf es mehr achten sollte (während jedes Ausgabetoken am Decoder generiert wird). Bei Transformer-Modellen existiert dieses Problem nicht, da sie durchgängig auf Selbstaufmerksamkeit [10] setzen – jede Encoder- und Decoder-Schicht hat Aufmerksamkeit.
Modelle mit dem Aufmerksamkeitsmechanismus dominieren derzeit die Führungsgremien für abstrakte Zusammenfassungsaufgaben [11, 12]. Aufmerksamkeit ist nicht nur nützlich, um die Modellleistung zu verbessern, sondern hilft uns auch, den Endbenutzern des KI-Systems zu erklären, wo (im Quelltext) das Modell geachtet hat [13]. Genau das haben wir für eines unserer internen Produkte getan, um den redaktionellen Workflow noch wertvoller zu machen.

Für diesen speziellen Anwendungsfall haben wir ein Deep-Learning-Modell trainiert, um eine Zusammenfassung basierend auf einem Quelltext zu generieren. Pro vorhergesagtem Token (als Teil der Zusammenfassung) erhalten wir eine Verteilung der Aufmerksamkeitswerte über die Token im Ausgangstext. Wir haben die Aufmerksamkeitsvektoren zu einem Aufmerksamkeitswert pro Wort im Ausgangstext aggregiert, diese Werte geglättet und normalisiert. So haben wir für jedes Wort im Quelltext einen Aufmerksamkeitswert zwischen 0 und 1 erhalten (Abbildung 4 oben), den wir den Endnutzern per Texthervorhebung anzeigen. Je größer der Aufmerksamkeitswert, desto dunkler die Texthervorhebung und desto mehr Bedeutung hat das Modell dem jeweiligen Wort bei der Erstellung der Zusammenfassung beigemessen, wie in Abbildung 5 unten gezeigt [14].

Oft verlassen sich viele der Erklärungen auf die Intuition der Forscher, was eine „gute“ Erklärung ausmacht. Dies ist problematisch, da KI-Erklärungen häufig von Laien verlangt werden, die möglicherweise kein tiefes technisches Verständnis von KI haben, aber Vorurteile darüber haben, was nützliche Erklärungen für Entscheidungen in einem vertrauten Bereich darstellen.
Wir glauben und schlagen vor, dass Sie bei der Entscheidung, wie Sie Ihr KI-Modell Benutzern erklären, die damit interagieren, diese Erklärungen an die Bedürfnisse der Benutzer anpassen sollten. Idealerweise sollten Sie damit verschiedene Erklärbarkeitsmethoden testen und die Testumgebung sollte so weit wie möglich einem realen Aufbau ähneln, da dies hilft, wirklich zu verstehen, welche Erklärbarkeitsmethoden am besten funktionieren und warum. Sie sollten darauf abzielen, sowohl passive Metriken (z. B. haben die Benutzer mehr Änderungen an KI-Vorschlägen vorgenommen, waren sie schneller oder langsamer usw.) als auch direktes Feedback von Benutzern durch Interviews und Umfragen zu sammeln. Sie sollten jedoch auch Feedback sammeln, nachdem das Modell aktiv eingesetzt wurde, und immer bereit sein, Ihr Modell sowie seine Erklärbarkeitsfunktionen zu iterieren und zu verbessern.
WEITERLESEN:
- Nachhaltigkeit in einer digital vernetzten Welt erreichen
- Wie verbessert das digitale Bauen die Sicherheit und Nachhaltigkeit im Bausektor?
- Huawei veröffentlicht seinen Nachhaltigkeitsbericht 2020
- Wie KI die Nachhaltigkeit in der Gesundheitsbranche unterstützen kann
Nehmen Sie an unserem Vortrag auf dem Data Innovation Summit teil, um zu erfahren, wie wir Erklärbarkeitsmethoden für unsere Lösung zur Zusammenfassung von Rechtstexten ausgewählt haben und was wir dabei gelernt haben.
Entdecken Sie den Data Innovation Summit
Bibliographie
[1] Arrieta AB et al. (2020). Erklärbare künstliche Intelligenz (XAI): Konzepte, Taxonomien, Chancen und Herausforderungen für verantwortungsbewusste KI. Informationsfusion 58: 82–115. arXiv:1910.10045. Abgerufen von: https://arxiv.org/abs/1910.10045[2] Murdoch JW et al. (2019) Interpretierbares maschinelles Lernen: Definitionen, Methoden und Anwendungen, Verfahren der National Academy of Sciences, Von: https://arxiv.org/abs/1901.04592[3] Molnar C. (2021) Interpretierbares maschinelles Lernen: Ein Leitfaden, um Black-Box-Modelle erklärbar zu machen. Von: https://christophm.github.io/interpretable-ml-book/[4] Sundararajan, M., et al. (2019) „Die vielen Shapley-Werte zur Modellerklärung.“ Abgerufen von: https://arxiv.org/abs/1908.08474[5] Ribeiro, M. et al. (2016) „Warum sollte ich Ihnen vertrauen?: Erklärung der Vorhersagen eines beliebigen Klassifikators.“ Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM.[6] Bahdanau, D. et al. (2016). Neuronale maschinelle Übersetzung durch gemeinsames Lernen des Ausrichtens und Übersetzens. 3. Internationale Konferenz zum Lernen von Repräsentationen, ICLR 2015: https://arxiv.org/abs/1409.0473[7] Vaswani, A. et al. (2017). Attention is all you need. Fortschritte in neuronalen Informationsverarbeitungssystemen (S./S. 5998–6008)[8] Lihala, A. (2019) Aufmerksamkeit und ihre verschiedenen Formen. Blogpost auf Medium: https://towardsdatascience.com/attention-and-its-different-forms-7fc3674d14dc[9] Weng L. (2018) Achtung? Aufmerksamkeit! Blogpost auf Lil'Log: https://lilianweng.github.io/lil-log/2018/06/24/attention-attention.html#self-attention[10] Geeks für Geeks-Redakteure. (2020) Selbstaufmerksamkeit im NLP. Blogpost auf Geeks für Geeks: https://www.geeksforgeeks.org/self-attention-in-nlp/[11] Sanjabi, N. Abstrakte Textzusammenfassung mit aufmerksamkeitsbasiertem Mechanismus. Masterarbeit in Künstlicher Intelligenz: https://upcommons.upc.edu/bitstream/handle/2117/119051/131670.pdf[12] Ruder, S. Abstraktive Zusammenfassung. NLP-Fortschritt:http://nlpprogress.com/english/summarization.html[13] Wiegreffe, S. et al. (2019) Aufmerksamkeit ist keine Erklärung https://arxiv.org/abs/1908.04626[14] Norkute, M. et al. (2021). Auf dem Weg zu erklärbarer KI: Bewertung der Nützlichkeit und Auswirkung zusätzlicher Erklärbarkeitsfunktionen bei der Zusammenfassung von Rechtsdokumenten. Erweiterte Zusammenfassungen der CHI-Konferenz 2021 über menschliche Faktoren in Computersystemen. Association for Computing Machinery, New York, NY, USA, Artikel 53, 1–7. DOI: https://doi.org/10.1145/3411763.3443441
Folge uns auf LinkedIn und Twitter